The AI behind the curtain: deception in human-AI experiments
Experimental economists don’t deceive their subjects. It’s not legislated, but break the norm and don’t expect to be published. Here’s Andreas Ortmann (2019):
I open with a statement of fact: deception in the form of acts of commission, while still widespread in (social) psychology and business sciences such as marketing, is factually banned in laboratory experimental economics. This ban is not legislated but, until recently, was a social norm that the community of experimental economists had been able to reasonably enforce.
There are a few reasons for this norm. One is that if participants suspect they are being deceived, they will alter their behaviour and undermine the experimental results. An example of this is the famous Solomon Asch conformity experiments, in which those who believed they were being deceived were less likely to conform with the group.
Deception also creates an externality for other experiments. After being deceived in one experiment - as they discover when promises aren’t kept or in experimental debriefs - participants will be less trusting in future experiments, again changing their behaviour. In subject pools where people complete many experiments and surveys, regular deception could shift their expectations.
There is no norm against deception in psychology. Deception is common and often argued to be necessary for many experiments, albeit with explicit ethical frameworks and debriefing.
There is also no such norm in human-computer interaction research, as I have discovered over the last couple of years. This is not only deception by omission: not telling people everything about the experiment. Rather, there are many acts of commission, such as telling people things that are not true.
One common form of deception is that there is no actual AI. Rather, the participants are shown hand-crafted responses. I have seen this called “synthetic AI” or “simulated AI”, and in design circles it is often called the “Wizard of Oz” paradigm.
It also seems common for experimenters to tell the occasional lie to generate the desired response.
Below are examples of each, along with some questions they raise. I don’t have a firm view on some of this deception apart from a general desire to avoid it, so the below is more observation than a hardened view.
Synthetic AI
To run an experiment on human responses to an AI, you want an AI. But that’s a challenge. You need to procure or develop an AI to train on the task or data. Depending on the nature of the AI, you might also design an interface. There’s also no guarantee that your AI will have the features you desire, such as a certain error rate or error boundary.
In economics, this challenge typically leads to the use of statistical prediction tasks. Given a dataset about, say, student achievement, you develop a statistical model (which you then call an AI) to predict achievement based on other features of the student. With readily available datasets (such as those on Kaggle or in repositories such as the UC Irvine Machine Learning Repository), developing statistical models is bread-and-butter work for an economist. You can train a model on these well-structured datasets in a few lines of code.
These models typically outperform human judgement by a considerable margin. The optimal interaction is for the human to hand off the decision to the AI. These models are useful for algorithm aversion studies, but provide limited scope to examine collaborative decision making.
If you want a weaker model, you might withhold data from the model (as done in a recent paper I posted about on anchoring). This gives the human information the model doesn’t have. Ultimately, however, statistical prediction is only a subset of the space in which you might want to study human-AI interaction. That moves us into more complex domains where it’s not so easy to develop a model.
In experiments coming from the human-computer interaction field, you do see statistical models, but often the experiments require a richer environment. And that’s where they turn to deception via synthetic AI.
One example of synthetic AI is in Buçinca et al. (2021), who examined whether triggering slow thinking can increase engagement with explanations of AI recommendations. The authors created a task where participants were shown a picture of a meal and information on the main ingredients. Participants were then asked what ingredients to substitute to make it low-carb while maintaining the original flavour.
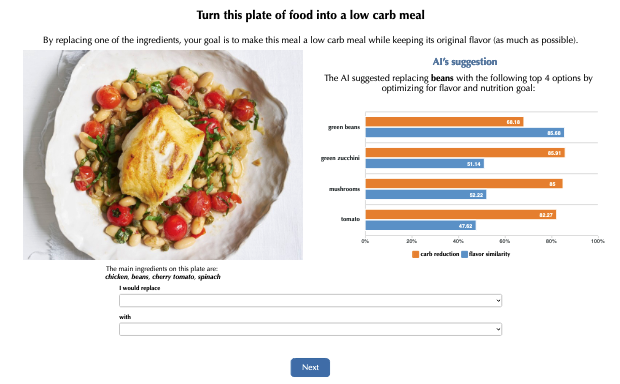
And how was this AI developed? The authors write:
We designed a simulated AI for the experiment, which had 75% accuracy of correctly recognizing the ingredient with the highest carbohydrate impact in the image of the meal. Note that we did not train an actual machine learning model for this task because we wanted to have control over the type and prevalence of error the AI would make.
This is one of the more direct statements that the AI was simulated rather than built. But even where less explicitly stated, it is common practice.
The question then becomes what participants believe about this scenario. Do they believe an AI is actually delivering these suggestions and associated explanations? To the extent they don’t, does this affect their likelihood of following the AI recommendation? Are you losing a degree of control over the participant’s mental model?
Some researchers in human-computer interaction do go the extra mile of developing a more complex model - and full praise to them. As an example, Lai et al. (2022) developed a neural architecture to classify Wikipedia comments and Reddit hate speech. The architecture allowed identification of the rationale, communicated through highlights of the relevant words in the text. It looks like a lot of effort, but it avoids deceiving participants. It also looks like a more ecologically valid experimental setup. That would boost my confidence in the results.

To avoid deception, some researchers get creative. Logg et al. (2019) wanted to test whether algorithm aversion was due to aversion to algorithms or external advice. They needed to deliver identical predictions to experimental participants (to maintain experimental control) while describing the advice as coming from either an algorithm or a human.
In the first experiment in the paper, 202 participants were asked to estimate the weight of a person in a photo. Everyone received advice, described as coming from either an algorithm or a person. The precise wording was either:
An algorithm ran calculations based on estimates of participants from a past study. The output that the algorithm computed as an estimate was: 163 pounds.
The average estimate of participants from a past experiment was: 163 pounds.
Both statements are technically true, though calling averaging an algorithm likely creates a gap between technical accuracy and lay interpretation.
The word “algorithm” is stretched even more in Experiment 1C, a task to estimate a person’s attractiveness from another perspective based on a text description. The wording in each condition was:
An algorithm estimated this (wo)man’s attractiveness (humor/ enjoyableness) from Mike’s (Julia’s) perspective. The algorithm’s estimate was: X
In another study, 48 people estimated this (wo)man’s attractiveness (humor/enjoyableness) from Mike’s (Julia’s) perspective. Their estimate was: X
Again, averaging is the “algorithm”.
Logg et al. (2019) described their choice of procedure as allowing them to avoid deception. I am not convinced, as the word “algorithm” triggers expectations that don’t match reality. If someone told me an algorithm was estimating attractiveness, I would assume something more sophisticated than averaging estimates from humans. I’d likely assume a text analysis model.
One mitigating factor is that this experiment ran pre-ChatGPT in 2019. Participants might not immediately imagine a text analysis algorithm. But in 2026 I’d assume exactly that and would respond based on that assumption. This raises the question: if participants couldn’t picture a text analysis algorithm in 2019, what were they assuming?
Much recent literature actually uses AI, in the form of ChatGPT and other LLMs. It’s finally easy to get an “AI” for almost any task. The deception is fading away, but that comes at the cost of control. I haven’t seen many ChatGPT experiments that tell me something useful about human-AI interaction or that aren’t already outdated on publication. But that’s a topic for a different post.
Misrepresented AI
Although I don’t like it, I understand the appeal of synthetic AI. It’s hard to create tasks where an actual AI does what you claim. For many specific questions, it’s beyond the technical capability of the experimenters.
But the deception isn’t limited to synthetic AI. The AI is often misrepresented.
Here’s an example from Rastogi et al. (2022), who examined whether they could de-anchor experimental participants from AI advice. I posted about this paper previously. (I should also note I didn’t select the papers in this post because they’re particularly problematic. Rather, they’re papers with interesting ideas that I am familiar with.)
The authors write:
To induce anchoring bias, the participant was informed at the start of the training section that the AI model was 85% accurate (we carefully chose the training trials to ensure that the AI was indeed 85% accurate over these trials), while the model’s actual accuracy is 70.8% over the entire training set and 66.5% over the test set. Since our goal is to induce anchoring bias and the training time is short, we stated a high AI accuracy.
The “training trials” shown to participants were not a representative sample of the model’s performance. They were selected so that the 85% claim was true within those training trials. But the model was not 85% accurate over the full training set, where its accuracy was 70.8%. Nor was it that accurate over the test set, where its accuracy was 66.5%.
The gap was even larger in the actual experimental task. The authors included probe trials where they flipped some AI predictions shown to participants. The AI predictions shown to participants in this phase were 58.3% accurate, far below the 85% figure participants had just been given.
So participants were not merely “anchored” by an arbitrary AI recommendation. They were first given a selectively favourable impression of the AI’s reliability, then exposed to a test phase where the AI advice was less reliable.
The authors defend this approach:
[T]his disparity between stated accuracy (85%) and true accuracy (70.8%) is realistic if there is a distribution shift between the training and the test set, which would imply that the humans’ trust in AI is misplaced.
But this makes the experiment harder to interpret. The “anchoring” is justified by what participants were told or shown. You can’t study anchoring bias when you’ve deliberately created the conditions for justified trust.
The engineering of deceptive scenarios is a recurring theme across the literature. Here are a few more examples. Yin et al. (2024) told participants that responses came from either a human or AI, irrespective of the actual source. Longoni et al. (2023) took real news articles on AI failures and substituted either a human or an AI as the cause of the problem. Khadpe et al. (2020) used human workers to simulate chatbots, telling participants that these “AI” workers they were interacting with were modelled on a toddler, middle schooler, young student, recent graduate or trained professional.
In each case you’re relying on there being no “smell” to the AI outputs. You’re relying on participants believing your statement even when the evidence in front of them might point elsewhere.
Then there is contamination of the subject pool. Many participants in these studies come from platforms such as Amazon Mechanical Turk, where many workers spend their day doing studies like these. How many times do they read in an experimental debrief that the wool was pulled over their eyes? What does that do to their future interactions? Given that human-computer interaction researchers and experimental economists are fishing in the same stream, practices such as this can impose a negative externality across multiple fields.
I don’t know the answers, but these deceptive practices introduce another layer of doubt as to whether we should trust these results.
What to do?
The human-computer and human-AI interaction literature is shaky. As I noted elsewhere, experimental practices look like those in psychology circa 2005: small sample sizes, no pre-registration, no data openness. All the hallmarks of a replication crisis.
At the same time, the field is flooded. My Google alerts and literature searches deliver dozens of papers every week, and I’m not catching all of them. Most are trivial, but even when they have an interesting or useful hypothesis, I typically don’t trust them.
On top of this, the literature is accumulating findings from fake AI that may not describe interaction with real AI at all. The findings are useful and generalise only if the deception was successful and the substitute generated the same behaviour as the real thing. Those assumptions are rarely tested.
I don’t have a full solution to these problems, but one starting point is for researchers to slow down. The technical excuse for synthetic AI has weakened, as LLMs make it easier to build a working AI for an experiment. Most of the deception could be eliminated with some thought and work, and we’d get a much more valuable literature.